
"He was short of his age: with rather bow-legs, and little, sharp, ugly eyes."
-Charles Dickens, Oliver Twist

A month before the election, I was reading a critique of Clinton that described her as 'aloof'. I have read several interviews with Hillary and watched snippets of dozens of speeches and I find her to be empathetic and genuine on her core issues. Perhaps she reads differently to other people, but calling Clinton aloof seems to me to be coded language punishing her because she doesn't meet cultural standards for female figures as empathetic and nurturing.1 i.e. Hillary is too ambitious and too powerful, so she must be frigid, aloof, and scheming.2
That description prompted me to investigate more instances of gendered language in wider cultural discourse. I collected a massive amount of text from multiple sources and analyzed each one, looking for adjectives used in the same sentence as a male/female name, pronoun, or gendered noun to see what adjectives are used to describe each gender.
There is a methodology section at the end of this post. To get the basics though, look at this quote from Oliver Twist.
This sentence describes the Artful Dodger. Because there is a male pronoun 'he' in the sentence and no other pronoun, adjectives in this sentence describe males. A part-of-speech tagger is used to identify the part of speech of each word. 'Short', 'little', and 'sharp' are all adjectives in this sentence that will be marked down as describing a male. 'Ugly' will not be, because the part-of-speech tagger incorrectly identified it as an adverb.3
Here are the six sources I analyzed:
Below, I've prepared several interactive ways you can explore the resulting data.
The first shows adjectives in each source that commonly describe one gender. Adjectives typically associated with females are purple, and those associated with males are colored orange. You can change this so words are colored red if they are negative descriptions and blue for positive descriptions. Click the buttons at the top to switch between sources or to sort the words.
You might notice that the most gender-biased adjectives for both men and women are positive (try sorting by gender bias and coloring the blocks by sentiment). But while the most male-biased adjectives don't follow any particular theme—'creative', 'brutal', 'excellent', 'decent', 'iconic', 'genuine', etc.—the most female-biased adjectives are almost exclusively concerned with physical appearance. Excepting Austen's books, women are most commonly described by words such as 'beautiful', 'attractive', 'sexy', 'hot', and 'gorgeous'. While not unexpected, the extent of this is surprising. These words appear close to the top of each female wordlist in the visualization above (when sorted by gender-bias), whereas few of the most male-biased adjectives are about appearance.5
Try sorting by frequency and then looking for the first highly gender-biased word (dark purple/orange coloring) for each sex.6 Again, there's not much of a pattern for men but for women it is likely an appearance-focused adjective, a description of sexual availability ('single' and 'married' are very common descriptors for women), or 'pregnant'.
For a more whimsical look at the data, change the identity of the subject in the sentence below. Switching between hero/heroine and villain/villainess will provide random descriptions using positive or negative words, respectively. Try a few descriptions in each source to get a snapshot look at the language it uses.
Finding large bodies of text to analyze can be a bit difficult, and some of my choices for this project are out of convenience. Dickens and Austen are both in the public domain and available in easy-to-process form on the internet. The Slate corpus was collected by someone else and makes a nice stand-in for media. Twitter and the tv and movies subreddits were both readily available and representative of mass cultural discourse. That leaves kotakuinaction: a community more or less founded around members' deep-seated sexism that I thought would provide an interesting contrast to the other three modern sources (see footnote 4).
In an unsettling twist, the gamergate source is not obviously more sexist than the other two mass culture sources. All three primarily ascribe physical adjectives to women, along with an assortment of unfavorable mental characteristics. This next interactive lets you compare how words are used across the six sources. As you start to type on the input line, you'll see a list of adjectives that appear in the dataset. Hit the submit button to see the gender bias of a particular adjective in each dataset. You can also just watch as it displays random words.
Keep in mind that rare adjectives might only occur a few times in a particular source (words that appeared fewer than four times in a source were excluded from the dataset). Words that appear only rarely may be biased more out of coincidence than intent. Consistency across datasets, on the other hand, is suggestive of a real phenomenon. 'Vapid' has a strong, consistent bias across all of the modern datasets.
It is also worth bearing in mind that language is tricky. Just as it is insulting to describe an African-American person as 'articulate,' because this is a patronizing, back-handed jab at all African-Americans presented as a compliment, some words may be disproportionately used to describe women for the same purpose. I don't want to speculate on what words these might be as I am not a woman, but one of my reviewers suggests 'competent' fits the bill.
So far, I haven't tried to numerically summarize the sources as wholes, primarily because few reliable methods exist for doing so. The one measure we do have is sentiment. Sentiment is measured from -1, indicating a negative word, to +1. 'Horrific' has a sentiment of -1 while 'perfect' has a sentiment of 1.7 The bar graph below shows average sentiment in each source by gender.
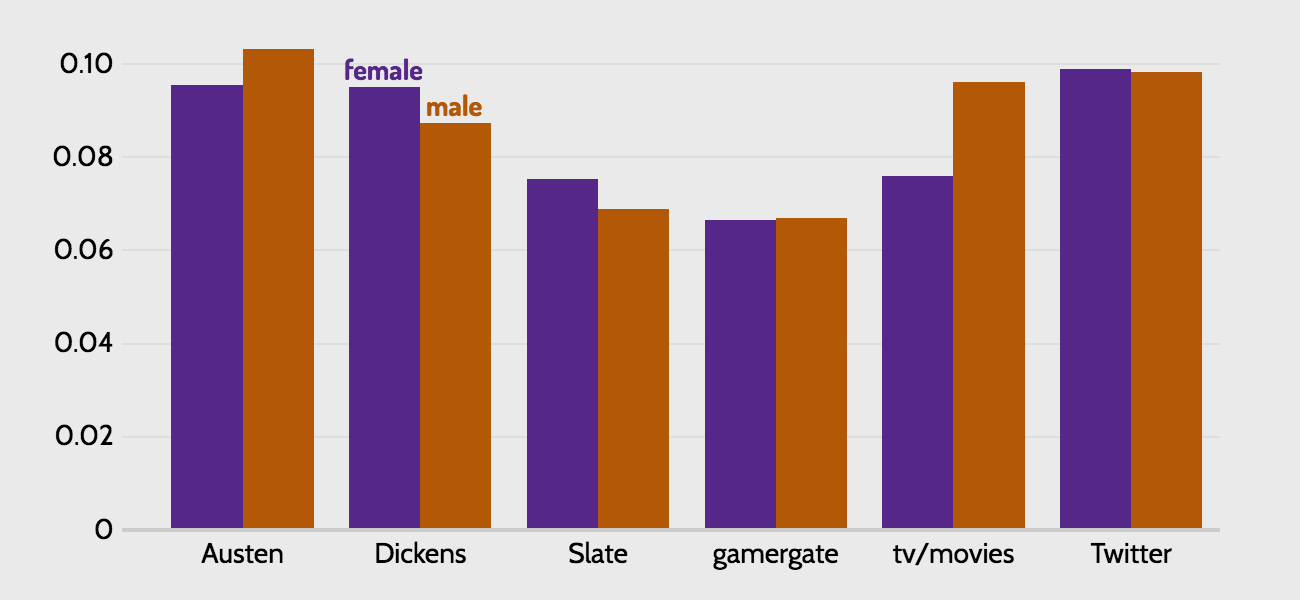
This graph suggests that every source is on average positive, and that there is little variation between the genders in any source save for the tv/movies subreddits. But this is somewhat misleading due to extremely common but for our purposes uninteresting words like 'much,' which has a sentiment of 0.2. This may not seem significant but 'much' appears more than 10,000 times in some sources, dramatically increasing average sentiment in that source.8
To get a more accurate read on the data, it makes sense to exclude extremely common words like 'much'. How many common words? Below I show what happens when I exclude the most common 1%, 2%, and 3% of words. From examining the words that are excluded at each step, the 2% graph is the most intuitively appealing to me, but a case could be made for any of the three (note that these three graphs are on a different scale than the one above, but are all on the same scale as each other).
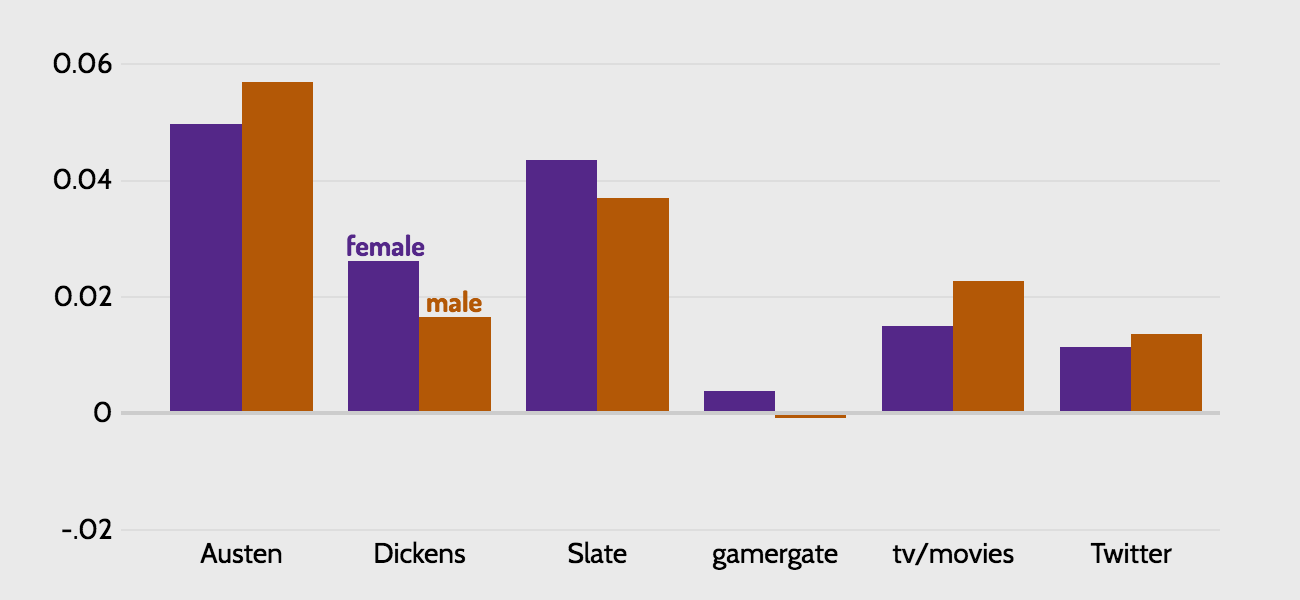
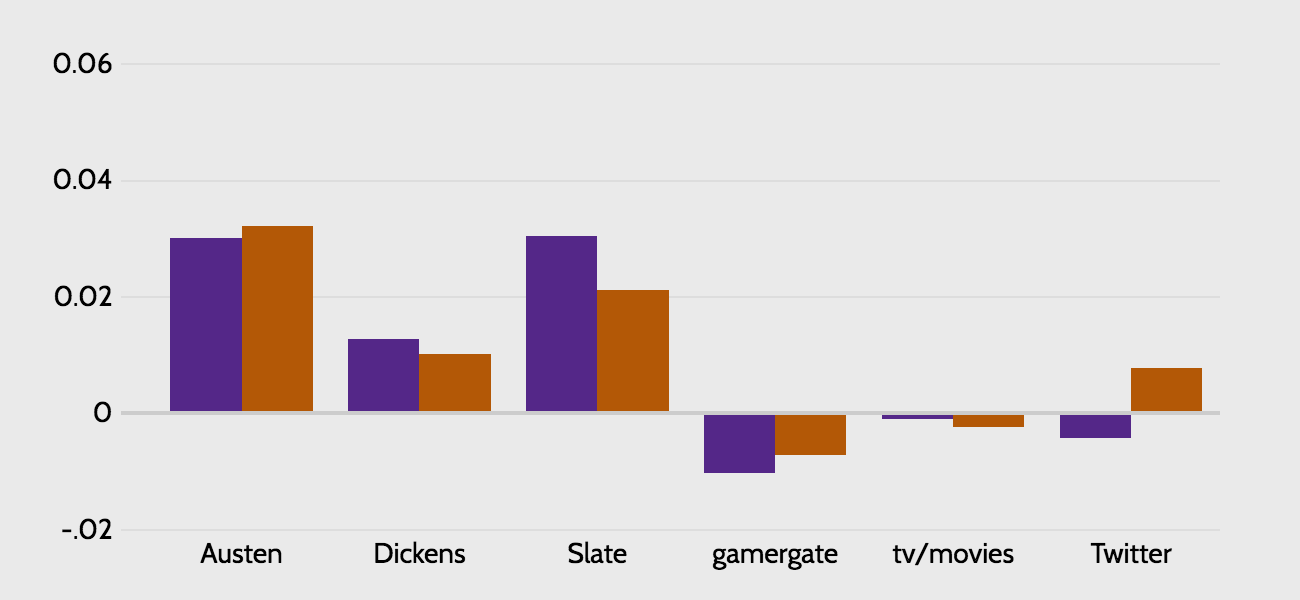
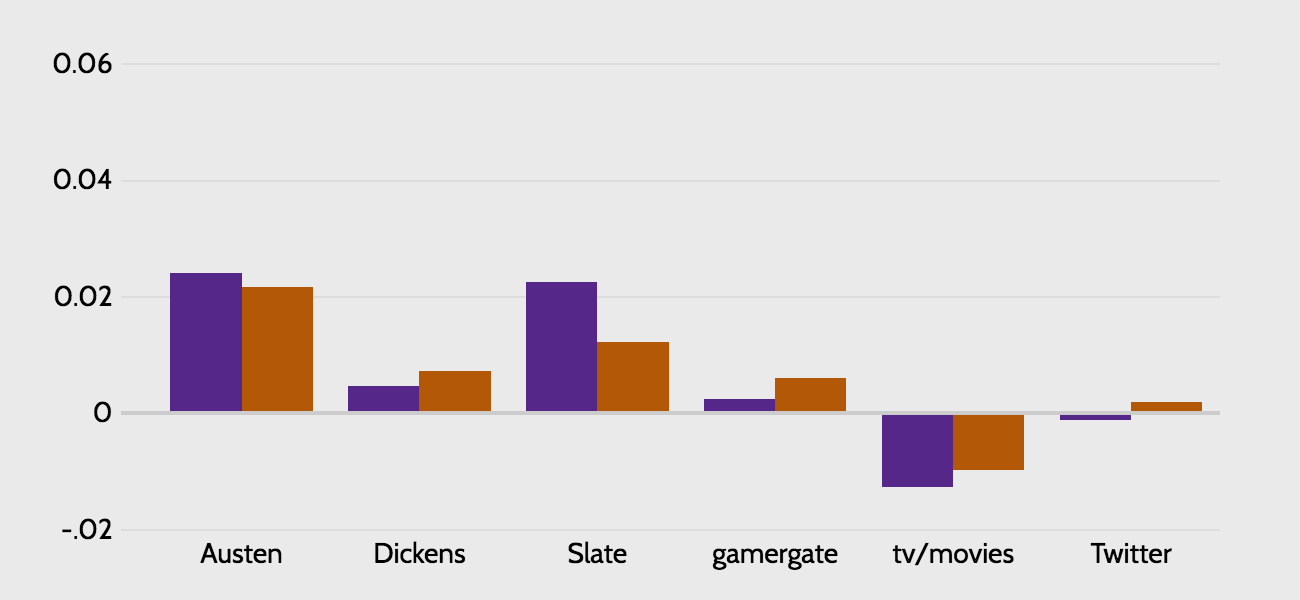
These graphs are substantially more interesting. While they are a bit sensitive to the threshold we choose to exclude words, two observations seem safe:
It's not demonstrably obvious that the gamergate source is dramatically more sexist than either the other reddit source or Twitter, which just goes to show that a remarkable degree of misogyny is culturally pervasive.
I used the NLTK and TextBlob packages for Python to do all the text processing for this project. The idea was to produce something reasonably accurate in a quick and dirty way, without having to resort to a lot of complicated grammar parsing.
First texts were tokenized and tagged using NLTK's default part of speech tagger. This tagger seems reasonable and I didn't feel a need to evaluate others, but there are a few misses I noticed. 'Dainty' is one case where the tagger frequently mistook an adjective for a noun.
One way to approach finding adjectives that describe males/females would be to parse sentences for noun phrases/pronoun phrases. This approach requires a significant amount of faith in the tagger and also in anticipating a number of different ways that such phrases can be constructed. I opted to do something much simpler and hope for approximately correct results. I simply separated each text into sentences and then looked in each sentence for a gendered noun, a pronoun, or a name. I used NLTK's corpus of names by gender to determine if a name was male or female (last names were discarded although there is the possibility that if a man, for example, was referred to only by last name and his last name is an identifiably female first name, that adjectives were misattributed). If a sentence contained both a male and a female subject, it was thrown out. If it contained only female or male subjects, adjectives in the sentence were collected and counted. Thus, some adjectives did not describe a person at all: "The man sat on the dainty pillow" adds one use of 'dainty' to the male column for that text. This approach works better on very large texts, which is why many existing corpora available in NLTK for example were not viable options.
Once all the adjectives were collected, they were stemmed using NLTK's Lancaster stemmer, which gave me better results on a number of words I tested with than the other canned options. Using the stemmed words I combined words like 'intelligent' and 'intelligently' for example. This didn't always work so you may still find more than one form of certain words (e.g. irritated and irritating). There are definitely problems with this approach. For example, the Lancaster stemmer consolidates 'wine' (presumably used as a description of color although possibly tagged incorrectly) with 'winning.'
Finally, metrics were calculated for each word. Words were assigned a sentiment using TextBlob's sentiment method. Gender bias is the ratio of the percentage of males described using a word in a given source to the percentage of females described with that word in the same source. Words used fewer than four times in a text were dropped from the dataset along with words that have a sentiment of zero. This is an attempt to eliminate adverbs (mistakenly tagged as adjectives) or common adjectives that don't really describe people. Unfortunately it catches a few interesting words too, but this winnowing is necessary to help with visual interpretation.